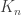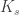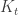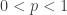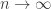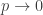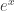The goal of this post is to prove the following elementary lower bound for off-diagonal Ramsey numbers ![R(s, t)]() (where
(where ![s \ge 3]() is fixed and we are interested in the asymptotic behavior as
is fixed and we are interested in the asymptotic behavior as ![t]() gets large):
gets large):
![\displaystyle R(s, t) = \Omega \left( \left( \frac{t}{\log t} \right)^{ \frac{s}{2} } \right).]()
The proof does not make use of the Lovász local lemma, which improves the bound by a factor of ![\left( \frac{t}{\log t} \right)^{ \frac{1}{2} }]() ; nevertheless, I think it’s a nice exercise in asymptotics and the probabilistic method. (Also, it’s never explicitly given in Alon and Spencer.)
; nevertheless, I think it’s a nice exercise in asymptotics and the probabilistic method. (Also, it’s never explicitly given in Alon and Spencer.)
The alteration method
The basic probabilistic result that gives the above bound is actually quite easy to prove, and is an example of what Alon and Spencer call the alteration method: construct a random structure, then alter it to get a better one. Recall that the Ramsey number ![R(s, t)]() is the smallest positive integer
is the smallest positive integer ![n]() such that every coloring of the edges of the complete graph
such that every coloring of the edges of the complete graph ![K_n]() by two colors (say blue and yellow) contains either a blue
by two colors (say blue and yellow) contains either a blue ![K_s]() or a yellow
or a yellow ![K_t]() .
.
Theorem: For any positive integer ![n]() and any real number
and any real number ![0 < p < 1]() , we have
, we have
![\displaystyle R(s, t) > n - {n \choose s} p^{{s \choose 2}} - {n \choose t} (1 - p)^{ {t \choose 2}}]() .
.
Proof. Consider a random coloring of the edges of ![K_n]() in which an edge is colored blue with probability
in which an edge is colored blue with probability ![p]() and yellow with probability
and yellow with probability ![1 - p]() , and delete a vertex from every blue
, and delete a vertex from every blue ![K_s]() or yellow
or yellow ![K_t]() . How many vertices will be deleted, on average? Since the expected number of blue
. How many vertices will be deleted, on average? Since the expected number of blue ![K_s]() ‘s is
‘s is ![{n \choose s} p^{ {s \choose 2} }]() , and the expected number of yellow
, and the expected number of yellow ![K_t]() ‘s is
‘s is ![{n \choose t} (1 - p)^{ {t \choose 2} }]() , it follows that the expected number of vertices to be deleted is at most their sum (it should be less since deleting one vertex may mean we do not have to delete others). Here we are using the fundamental fact that a random variable is at most (equivalently, at least) its expected value with positive probability, which is trivial when the sample space is finite.
, it follows that the expected number of vertices to be deleted is at most their sum (it should be less since deleting one vertex may mean we do not have to delete others). Here we are using the fundamental fact that a random variable is at most (equivalently, at least) its expected value with positive probability, which is trivial when the sample space is finite.
This means that, with positive probability, we delete at most the expected number. The result is a coloring of the complete graph on ![n - {n \choose s} p^{ {s \choose 2}} - {n \choose t} (1 - p)^{ {t \choose 2} }]() vertices with no blue
vertices with no blue ![K_s]() or yellow
or yellow ![K_t]() , hence
, hence ![R(s, t)]() must be greater than this number.
must be greater than this number.
Optimization
Now our goal is to choose close-to-optimal values of ![n, p]() . When
. When ![s = t]() it turns out that this method only gives a small improvement over Erdős’s classic bound
it turns out that this method only gives a small improvement over Erdős’s classic bound ![R(k, k) \ge 2^{k/2}]() (“the inequality that launched a thousand papers”), but when
(“the inequality that launched a thousand papers”), but when ![s]() is fixed and we are interested in the asymptotics as a function of
is fixed and we are interested in the asymptotics as a function of ![t]() then we can do quite a bit better than the obvious generalization of Erdős’s bound.
then we can do quite a bit better than the obvious generalization of Erdős’s bound.
We will choose ![p]() first. For large
first. For large ![t]() the important term to control is
the important term to control is ![{n \choose t} (1 - p)^{ {t \choose 2} }]() ; if this term is too large then the bound above is useless, so we want it to be small. This entails making
; if this term is too large then the bound above is useless, so we want it to be small. This entails making ![1 - p]() small, hence making
small, hence making ![p]() large. However,
large. However, ![{n \choose s} p^{ {s \choose 2} }]() will overwhelm the only positive term
will overwhelm the only positive term ![n]() if we choose
if we choose ![p]() too large. Since we are willing to lose constant factors, let’s aim to choose
too large. Since we are willing to lose constant factors, let’s aim to choose ![p]() so that
so that
![\displaystyle {n \choose s} p^{ {s \choose 2}} \approx \frac{n}{2}]()
since the positive contribution from ![n]() will still occur up to a constant factor. Using the inequality
will still occur up to a constant factor. Using the inequality ![{n \choose s} \le \frac{n^s}{2}]() (which is good enough, since
(which is good enough, since ![s]() is fixed) we see that we should choose
is fixed) we see that we should choose ![p]() so that
so that ![p^{ {s \choose 2} } \approx n^{1-s}]() , so let’s choose
, so let’s choose ![p = n^{- \frac{2}{s} }]() . This gives
. This gives
![\displaystyle R(s, t) \ge \frac{n}{2} - {n \choose t} (1 - p)^{ {t \choose 2} }]() .
.
Now we need to choose ![n]() . To do this properly we’ll need to understand how the second term grows. This requires two estimates. First, the elementary inequality
. To do this properly we’ll need to understand how the second term grows. This requires two estimates. First, the elementary inequality ![t! \ge \left( \frac{t}{e} \right)^t]() (which one can prove, for example, by taking the logarithm of both sides and bounding the corresponding Riemann sum by an integral; see also Terence Tao’s notes on Stirling’s formula) gives
(which one can prove, for example, by taking the logarithm of both sides and bounding the corresponding Riemann sum by an integral; see also Terence Tao’s notes on Stirling’s formula) gives
![\displaystyle {n \choose t} \le \left( \frac{en}{t} \right)^t]() .
.
Second, the elementary inequality ![1 - p \le e^{-p}]() (by convexity, for example) gives
(by convexity, for example) gives
![\displaystyle (1 - p)^{ {t \choose 2} } \le \exp \left( -n ^{- \frac{2}{s} } {t \choose 2} \right)]() .
.
Let me pause for a moment. I was recently not assigned this problem as homework in a graph theory course. Instead, we were assigned to prove a weaker bound, and only for ![R(3, t)]() . When I described the general argument to my supervision partner and supervisor, they commented on the “weird” (I forget the exact word) estimates it required, and didn’t seem particularly interested in the details.
. When I described the general argument to my supervision partner and supervisor, they commented on the “weird” (I forget the exact word) estimates it required, and didn’t seem particularly interested in the details.
These estimates are not weird! In order to get any kind of nontrivial lower bound it is necessary that ![n \to \infty]() , and in order to prevent the second term from overwhelming the first it is necessary that
, and in order to prevent the second term from overwhelming the first it is necessary that ![p \to 0]() . In this regime, to estimate
. In this regime, to estimate ![{n \choose t}]() when both
when both ![n]() and
and ![t]() goes to infinity requires more detail than the trivial bound
goes to infinity requires more detail than the trivial bound ![n^t]() , and the detail provided by the above estimate (which ignores the small corrective factors coming from the rest of Stirling’s formula) is exactly suited to this problem. And in order to estimate
, and the detail provided by the above estimate (which ignores the small corrective factors coming from the rest of Stirling’s formula) is exactly suited to this problem. And in order to estimate ![(1 - p)^{ {t \choose 2} }]() it is perfectly natural to use the exponential inequality, since the exponential is much easier to analyze (indeed, bounding expressions like these is in some sense the whole point of the function
it is perfectly natural to use the exponential inequality, since the exponential is much easier to analyze (indeed, bounding expressions like these is in some sense the whole point of the function ![e^x]() ). These are not contrived expressions coming from nowhere. The reader who is not comfortable with these estimates should read something like Steele’s The Cauchy-Schwarz Master Class and/or Graham, Knuth, and Patashnik’s Concrete Mathematics.
). These are not contrived expressions coming from nowhere. The reader who is not comfortable with these estimates should read something like Steele’s The Cauchy-Schwarz Master Class and/or Graham, Knuth, and Patashnik’s Concrete Mathematics.
Back to the mathematics. By our estimates, the logarithm of ![{n \choose t} (1 - p)^{ {t \choose 2} }]() is bounded by
is bounded by
![\displaystyle t \left( \log n - \log t + 1 - n^{- \frac{2}{s} } \frac{t-1}{2} \right)]() .
.
We want to choose ![n]() as large as possible subject to the constraint that this logarithm is bounded by
as large as possible subject to the constraint that this logarithm is bounded by ![\log n - \log 4]() or so. To get a feel for how the above expression behaves, let’s set
or so. To get a feel for how the above expression behaves, let’s set ![n = t^k]() for some
for some ![k]() . This gives
. This gives
![\displaystyle t \left( (k-1) \log t + 1 - t^{ - \frac{2k}{s} } \frac{t-1}{2} \right)]() .
.
The first term is ![O(t \log t)]() while the second term is
while the second term is ![O \left( t^{2 - \frac{2k}{s}} \right)]() , so to get these terms to match as close as possible we’d like
, so to get these terms to match as close as possible we’d like ![k]() to be slightly smaller than
to be slightly smaller than ![\frac{s}{2}]() . To get the logarithmic factor to match, we’ll set
. To get the logarithmic factor to match, we’ll set
![\displaystyle n = C \left( \frac{t}{\log t} \right)^{ \frac{s}{2} }]()
for some constant ![C]() . This gives a bound of
. This gives a bound of
![\displaystyle t \left( \frac{s}{2} \log t - \log \log t + \log C + 1 - C^{-\frac{2}{s}} \frac{t-1}{2t} \log t \right)]() .
.
The dominant term here is ![\left( \frac{s}{2} - \frac{1}{2} C^{ - \frac{2}{s} } \right) t \log t]() . We’d like this to be less than
. We’d like this to be less than ![\log n - \log 4]() , which requires the coefficient of this term to tend to zero. But as long as it does so sufficiently quickly, modifying
, which requires the coefficient of this term to tend to zero. But as long as it does so sufficiently quickly, modifying ![C]() beyond that will only lead to a constant change in
beyond that will only lead to a constant change in ![n]() (which is the main contribution to our lower bound), so we’ll cheat a little: we’ll make the coefficient negative so it overwhelms the other terms, which will ensure that its exponential tends to zero, giving an estimate
(which is the main contribution to our lower bound), so we’ll cheat a little: we’ll make the coefficient negative so it overwhelms the other terms, which will ensure that its exponential tends to zero, giving an estimate ![R(s, t) = \left( \frac{1}{2} - o(1) \right) n]() . This requires that
. This requires that ![s < C^{ - \frac{2}{s} }]() , hence
, hence ![s^{ - \frac{s}{2} } > C]() , so we will take
, so we will take
![\displaystyle n = \frac{1}{2} \left( \frac{t}{s \log t} \right)^{ \frac{s}{2} }]() .
.
This gives the final estimate
![\displaystyle R(s, t) = \Omega \left( \left( \frac{t}{\log t} \right)^{ \frac{s}{2} } \right)]()
as desired, where the implied constant is something like ![\frac{1}{4} s^{ - \frac{s}{2} }]() (although I have made no particular effort to optimize it).
(although I have made no particular effort to optimize it).
As for the question of what is currently known, see this MO question. Up to logarithmic factors, it seems the best known lower bound grows like ![\tilde{\Omega} \left( t^{ \frac{s+1}{2} } \right)]() (which is what the local lemma gives), while the best known upper bound grows like
(which is what the local lemma gives), while the best known upper bound grows like ![\tilde{O} \left( t^{s-1} \right)]() , and the latter is conjectured to be tight. For
, and the latter is conjectured to be tight. For ![s = 3]() a result of Kim gives the exact asymptotic
a result of Kim gives the exact asymptotic
![\displaystyle R(3, t) = \Theta \left( \frac{t^2}{\log t} \right)]() .
.